
はじめに
こんにちは。この記事ではWeb3に初めて参加するデータアナリスト、Web3の分析チームを立ち上げようとしている、あるいはWeb3のデータ全般に興味を持っている方を対象に、業界全体を包括的にまとめていくことを想定しています。
Web2ではAPIやデータベース、機械学習モデルなどを利用する最低限の知識があることを想定して記事を進めていきます。
ここでは大きく3点の考え方を押さえておきましょう。
- なぜオープンデータ・パイプラインはデータ作業のやり方を変えるのか?
- Web3データスタックに沿ったツールの概要とその活用方法
- Web3データチームで持つべき基本的な考慮事項とスキル
本記事は、以下「[2022] Guide to Web3 Data: Thinking, Tools, and Teams」を基盤に作成されています。https://ath.mirror.xyz/w2cxg5OP1OEcqvSgsEjSSyKRJhPmam0w-fXGogiG-8g
Web2とWeb3のデータの考え方の違い
ここではWeb2において、データをどのように構築し、それらをどう参照し、アクセスするかを要約します。単純化したデータパイプラインとして4つのステップを用意しました。
- イベントAPIトリガー(何らかのツイートが送信される)
- データベースへの取り込み(既存のユーザーモデルへの接続/状態の変化)
- 特定の製品/分析ユースケースのためのデータ変換(返信の追加/時間経過によるエンゲージメントメトリクスの追加)
- モデルの学習と展開(Twitterフィードのキュレーション用)
データがオープンソース化されるのは、変換が行われた後だけです。Kaggle(1000以上のデータサイエンス/データエンジニアリングのコンテスト)やHugging Face(26,000の一流のNLPモデル)のようなコミュニティは、企業がより良いモデルを構築するために公開データのサブセットを使用しています。オープンストリートマップのように、先の3つのステップでデータを公開しているドメイン固有のケースもありますが、これらはまだ書き込み権限に制限があります。
ここではっきりさせておきたいのは、私はデータについてだけ話しているのであって、Web2がオープンソースを全く持っていないと言っているのではありません。
他の多くのエンジニアリングの役割と同様に、Web2データにはパイプラインを構築するためのオープンソースのツールが大量にあります。例えばdbt、anything apache、TensorFlow)。
これらのツールはオープンソースであるものの、実際の詳細なデータはクローズドな状況です。
Web3ではそのデータすらもオープンソースになります。
これは、もはやデータサイエンティスト、アナリスト、データエンジニアもオープンに働くことができることを意味しています。
Web2とWeb3で違うオープンデータのサイクル
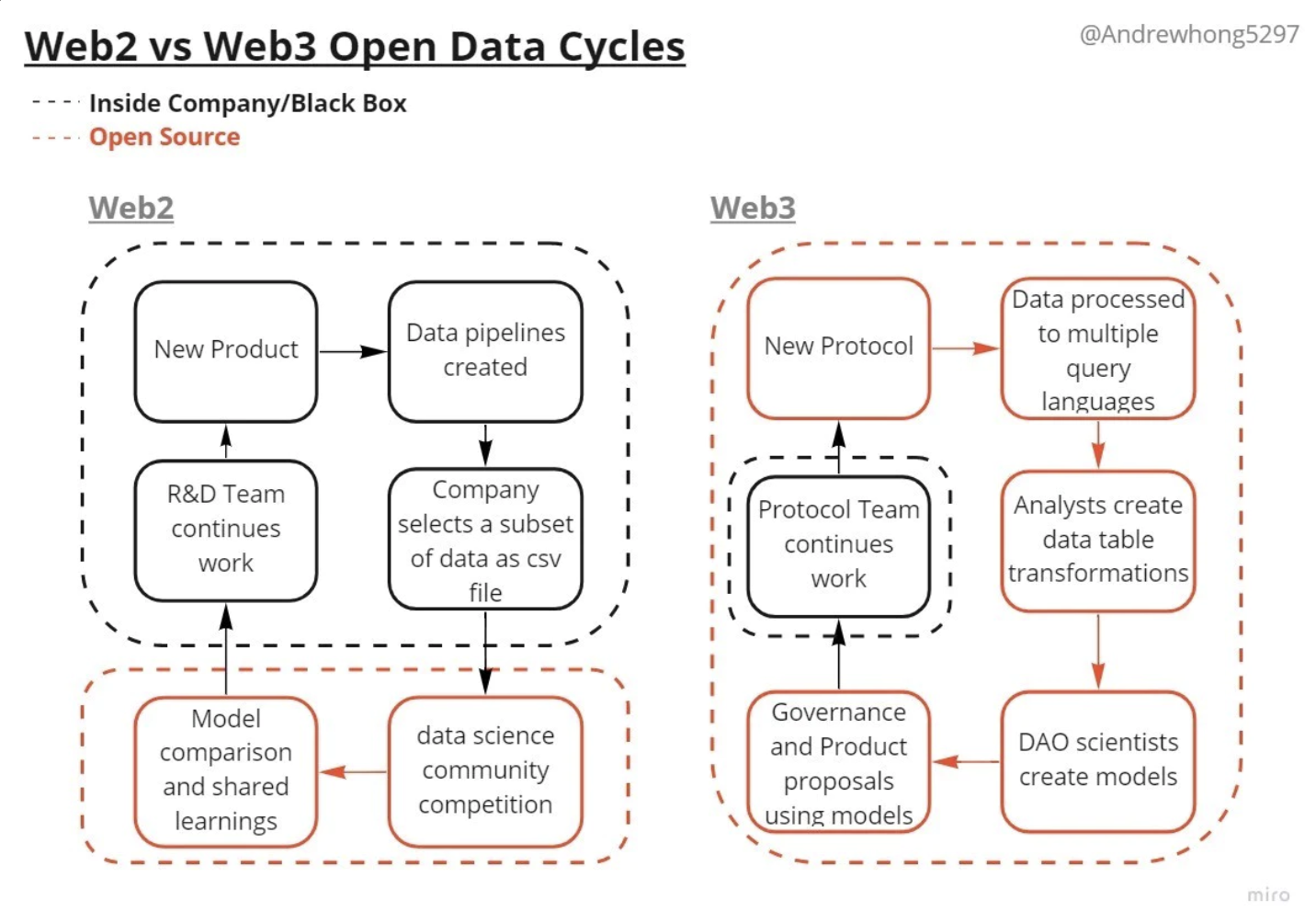
仕事の形は、Web2データのダムからWeb3データの川、三角州、海へと変化しています。
この新しいサイクルの重要なポイントは、エコシステム内のすべての製品やプロトコルに一度に影響を与える点です。
Web3アナリストがどのように連携しているか、一例を見てみましょう。
もしこれらがNasdaqのような典型的な取引所であれば、各取引所は10kまたは何らかのAPIで独自のデータを報告し、capIQのような他のサービスがすべての取引所データをまとめる作業を行い、そのAPIにアクセスするために$$を課金するでしょう。そして、capIQのような他のサービスが、取引所のデータをまとめて、APIにアクセスするための費用を請求します。たまに、イノベーションコンペティションを開催して、将来的に追加データ/チャート機能を課金できるようにするかもしれません。
Web3 取引所では、代わりにこのようなデータフローがあります。
- dex.tradesはDune上のテーブルで、DEXのスワップデータが集約されています(多くのコミュニティの分析エンジニアによって長い時間をかけてまとめられました)。
- データアナリストがやってきて、コミュニティのオープンソースクエリの束を使用してダッシュボードを作成すると、DEX業界全体の概要が公開されます。
- たとえすべてのクエリが1人の人間によって書かれたように見えても、それを正確にまとめるためにどこかのディスコードで膨大な議論があったことは間違いないでしょう。
- DAOのサイエンティストはダッシュボードを見て、独自のクエリでデータをセグメント化し、 ステーブルコインなどの特定のペアを調べ始めます。ユーザーの行動やビジネスモデルを見て、仮説を立て始めるのです。
- サイエンティストは、どのDEXが取引量の大きなシェアを占めているかを見ることができるので、新しいモデルを考え出し、ガバナンスパラメータの変更を提案して、オンチェーンで投票・実行させます(提案例については、こちらのアレックス・クローガー氏にお願いしています)。
- その後、私たちはいつでも公開クエリ/ダッシュボードをチェックして、その提案がより競争力のある商品を生み出したかを確認することができます。
- 将来、別のDEXが登場したら(あるいは新しいバージョンにアップグレードしたら)、このプロセスは繰り返されるでしょう。誰かが、このテーブルを更新するための挿入クエリを作成します。そうすると、すべてのダッシュボードやモデルに反映されます(誰も戻って手動で修正/変更する必要はありません)。他のアナリストや科学者は、アレックスが既に行った作業を基にすればよいのです。
データ理解や利活用に関するディスカッションやデータ同士のコラボレーション、予測などに利用される機会学習は、エコシステム内で共有されてPDCAが高速で回っていきます。
例えばあるアナリストは、これまでさまざまなデータに触れ、エコシステム内でも初期に膨大な貢献をすることでデータの燃え尽き症候群に陥る可能性があります。
しかし、エコシステム内の誰かがデータ処理を進め続ける限り、他の全員が利益を得ることができます。
(この場合の報酬設計は重要になってくるが、ここではここでは割愛します)
データ処理を推し進めること自体は、必ずしも複雑で困難なものである必要はなく、ENS reverse resolverを簡単に検索できるようにするユーティリティ機能や、CLIコマンド一つでほとんどのgraphQLマッピングを自動生成するようなツールの改善である場合もあります。これらはすべて、誰もが再利用可能であり、製品のフロントエンドや個人的な取引モデルでAPIを利用するために適応させることもできます。
このようにWeb3によって広がる可能性は素晴らしいものである一方で、まだこのサイクルはそれほどスムーズに回っていません。この背景には、データエンジニアに比べ、データアナリストやサイエンス側のエコシステムが未成熟であることも関連します。その理由としては、
- データエンジニアリングは、クライアントRPC APIの改善から基本的なSQL/graphQLのアグリゲーションまで、何年にもわたってWeb3の中心的な焦点でした。TheGraph や Dune のような製品への取り組みが、彼らがこれに注いできた努力を如実に物語っています。
- 例えば、Uniswap だけを分析する方法は理解できても、アグリゲータや他の DEX、異なるトークンタイプをミックスして分析する方法については、なかなか理解が進みません。その上、このようなことを行うためのツールは昨年まで存在しなかったのです。
- データサイエンティストは、基本的に生のデータダンプに行き、そのすべてを単独で作業する(独自のパイプラインを構築する)ことに慣れています。しかし、パイプラインの早い段階でアナリストやエンジニアと密接に、そしてオープンに仕事をすることに慣れているとは思えません。私自身、この点を理解するのに時間がかかりました。
Web3データコミュニティでは、一緒に仕事をするという新たなワークスタイルを学ぶだけでなく、この新しいデータ構造の中でどのように仕事をするかも学ぶこともできます。
インフラをコントロールしたり、Excelからデータレイクやデータウェアハウスに徐々に移行したりすることはもうしません。分析チームは、基本的にデータ・インフラストラクチャの深淵で活動することとなります。
バリエーションが増加していくデータツール
以下のカオスマップのように、データツールがさまざまあることが確認できます。
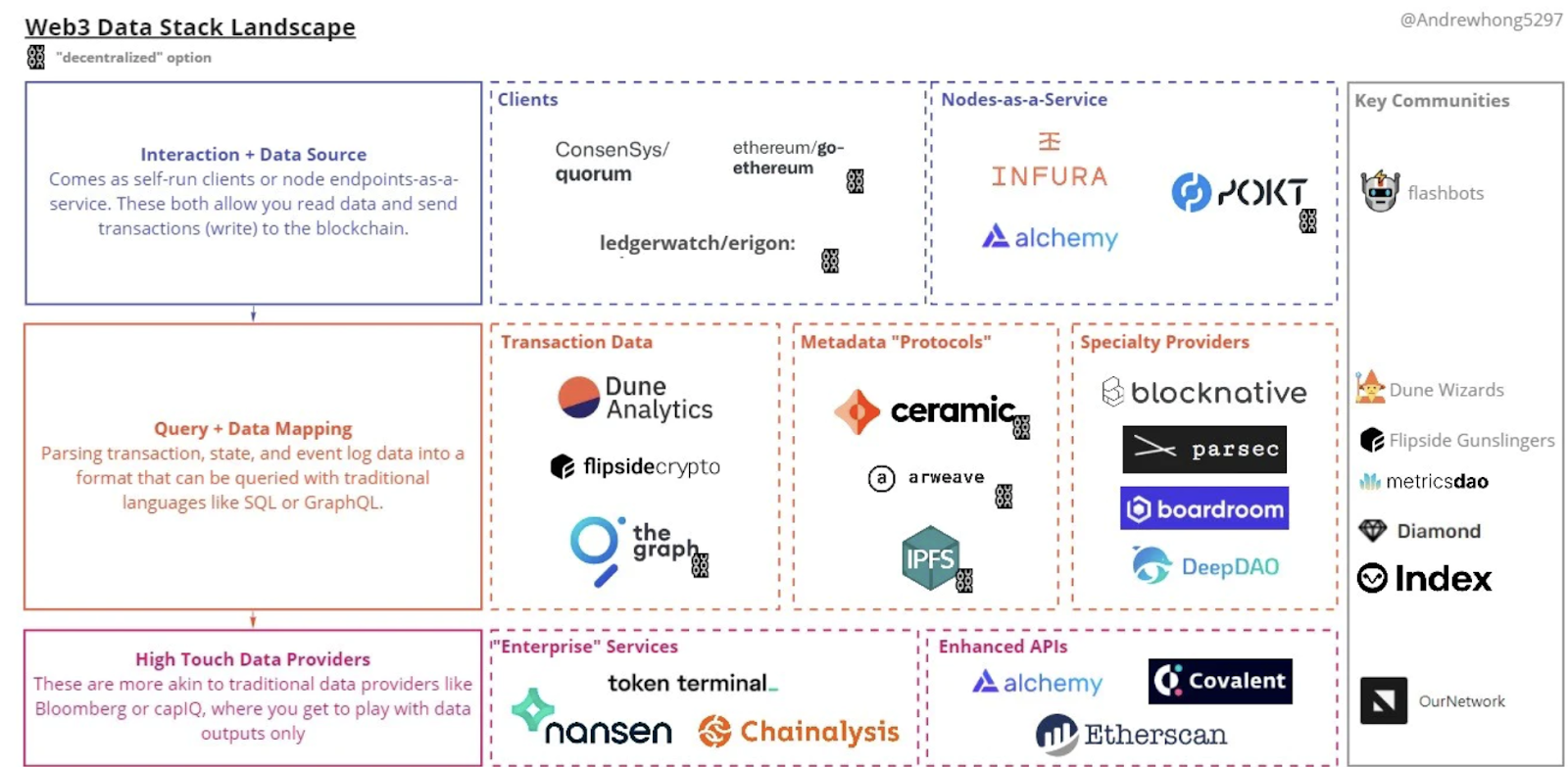
このカオスマップは業界全体やサービス全てをカバーするものではありません。あくまで、イーサリアムのエコシステムを参照することができるものの代表例をあげています。
ブロックチェーン分析プラットフォームの概要
このマップにおけるそれぞれのレイヤーやカテゴリーをどのような場合に使用するのかを解説します。

- Interaction + Data Source(インタラクション+データソース):フロントエンド、ウォレット、下位レイヤーへのデータインジェクションに使用されます。
- クライアント:イーサリアムのクライアントとなるこれらは、簡単に言えばイーサリアムを利用するために利用するソフトウェアみたいなものです。イーサリアムの基本的な実装は同じですが、各クライアントは異なる追加機能を備えています。
- 例えばErigonはデータの保存と同期が最適化されている点が強みであり、Quorumはプライバシーチェーンのスピニングをサポートしています。
- クライアントに関する解説については、こちら(https://techacademy.jp/magazine/17397#:~:text=Geth%E3%81%AFEthereum%EF%BC%88%E3%82%A4%E3%83%BC%E3%82%B5%E3%83%AA%E3%82%A2%E3%83%A0%EF%BC%89%E3%81%A7,%E3%82%82%E3%81%A3%E3%81%A8%E3%82%82%E5%88%A9%E7%94%A8%E3%81%95%E3%82%8C%E3%81%A6%E3%81%84%E3%81%BE%E3%81%99%E3%80%82)のテックアカデミーの記事が参考になります。
- Nodes-as-a-Service(ノーズ・アズ・ア・サービス):これまでイーサリアムのネットワークを管理するために、既存のAWSやGCPなどといった中央集権型のサービスを利用するという矛盾が発生していました。それらを全て分散型のノード上で管理していくことで、非中央集権型のサービスの完成形へと繋がります。そのためのノードを提供するサービスとして注目されているのがNode-as-a-Service(NaaS)です。どのクライアントを実行するかは選択できませんが、これらのサービスを利用することで、ノードやAPIのアップタイムを自分で管理するという煩わしさを削減できます。
- クライアント:イーサリアムのクライアントとなるこれらは、簡単に言えばイーサリアムを利用するために利用するソフトウェアみたいなものです。イーサリアムの基本的な実装は同じですが、各クライアントは異なる追加機能を備えています。
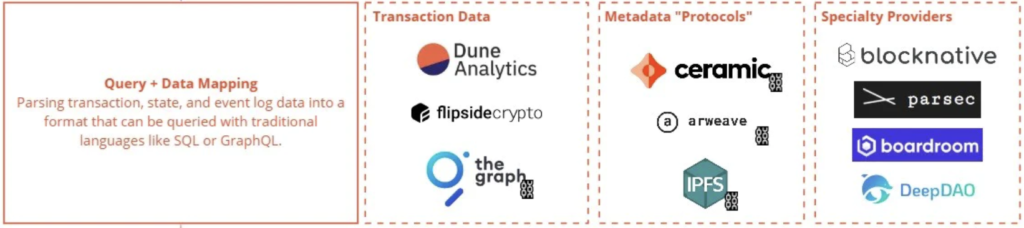
- Query + Data Mapping(クエリ + データマッピング):このレイヤーのデータは、コントラクトでURIとして参照されるか、コントラクトABI(Contract Application Binary Interfaceであり、イーサリアムエコシステムに対して、チェーンの外側または内部からアクセスするための標準装備を指す:こちらを参照)を使用してトランザクションデータをバイトからテーブルスキーマにマッピングしたものである。
- コントラクトABIは、コントラクトに含まれる関数やイベントを知ることが可能です。これがなければ、コントラクトトランザクションをリバースエンジニアリング/デコードすることはできませんそうでなければ、見えるのはデプロイされたバイトコードだけだからで。
- トランザクションデータ:これらは最も一般的に使用され、主にダッシュボードやレポートに使用される。theGraphとFlipside APIは、フロントエンドでも使用される。テーブルの中には、コントラクトを1:1でマッピングしたものや、スキーマで特別な変換を許可しているものも存在している。
- メタデータ・プロトコル:これらは実際のデータ製品ではないが、DID(Decentralized ID:非中央集権な状態での自身やファイルのID)の保存やファイル保存のために存在する。
- スペシャリティ・プロバイダー:メンプール・データのBlocknativeやオンチェーン取引データのParsecなど、非常に堅牢なデータ・ストリーミング製品もあります。また、DAO(Decentralized Autonomous Organzation)のガバナンスや財務データのように、オンチェーンとオフチェーンの両方のデータを集約するものもあります。

- ハイタッチデータプロバイダー:データプロバイダーが提供するデータは、クエリや変換はできないが、面倒なことはすべてやってくれます。
- 「エンタープライズ」サービス:ベンチャーキャピタル、調査員、記者などは、これらのサービスをよく利用するでしょう。Nansenのウォレット・プロファイラーやChainanalysisのKYT(Know Yout Transaction)を使えば、ウォレットやウォレットリレーションシップに深く入り込むことができます。また、Tolken Terminalを使用すると、大量のプロジェクトやチェーンについて、すぐに使える美しいグラフを表示することができます。
- Enhanced API:ERC20トークンのすべてのトークン残高や、指定されたアドレスのコントラクトABIを引き出すなど、多くのクエリを1つにバンドルした製品です。
Web3に必要不可欠な分析コミュニティとは?
これらのツールに加え、強力で傑出したコミュニティがなければ、Web3は成り立ちません。各レイヤーの隣に、トップコミュニティをピックアップしています。
- Flashbots:トランザクションを保護するためのカスタムRPC(Remote Procedure Call)からプロフェッショナルなホワイトハット・サービスまで、あらゆるMEV(Miner Extractable Value)に取り組んでいます。
- 参加方法:ドキュメントを読んで、どのバーチカルに興味があるかを判断し、Discordに参加する。
- 連絡先:Bert Miller
- Dune Wizards:Duneデータのエコシステムに重要な貢献をした、厳選されたウィザードたちのコミュニティーです。
- Flipside Gunslingers:Web3データのエコシステムに重要な貢献をした、厳選されたガンスリンガーたちです。
- 参加方法: Discordから始めて、クールなカスタムレポートを作成する
- 連絡先:エリックまたはGJ
- MetricsDAO:エコシステムを横断し、複数のチェーンで様々なデータバウンティに取り組んでいます。
- DiamondDAO:DAOのガバナンス、財務、トークン管理に関するステラデータサイエンスワーク。
- 参加方法: 文字通り、こちらに「参加」のページがある。
- 連絡先:Christian Lemp
- IndexCoop:暗号で最高のインデックスを作成するために、多くのトークンとドメイン固有の分析を行っています。
- 参加方法: Discordに参加し、メタバースインデックス(MVI)のような彼らのインデックス提案を読んでください。
- 連絡先:BigSkyまたはJD Cook
- OurNetwork:プロトコルやその他のバーティカルを毎週一貫してカバーしています。
- 参加方法:ニュースレターを購読し、優れた分析を行えば、いずれは我々の電報に載ることになるでしょう😉。
- 連絡先:Spencer Noon
これらのコミュニティのどれもが、Web3のエコシステムをより良くするために多くの仕事をしてきました。コミュニティがある製品は、100倍のスピードで成長することは言うまでもありません。これは、まだ十分に評価されていない部分もあります。しかしその価値は、これらのコミュニティの中で何かを作り出さない限り理解できない部分が多いのも事実です。
まとめ
いかがでしたでしょうか?
情報が枯渇しているWeb3業界の中でも現状はニッチな「データ分析」の業界を包括的に解説しました。こちらの記事はAndrew Hongの以下の記事がベースとなっています。
https://ath.mirror.xyz/w2cxg5OP1OEcqvSgsEjSSyKRJhPmam0w-fXGogiG-8g
実は海外ですらまだデータ分析に関する情報は乏しい状況なので、Fungible Analysisで一緒に最先端の情報と、包括的な情報を蓄えていきましょう。
こちらの記事が参考になった方は是非Twitterやご自身のコミュニティーでご共有・ご拡散いただけますと幸いです。









コメント